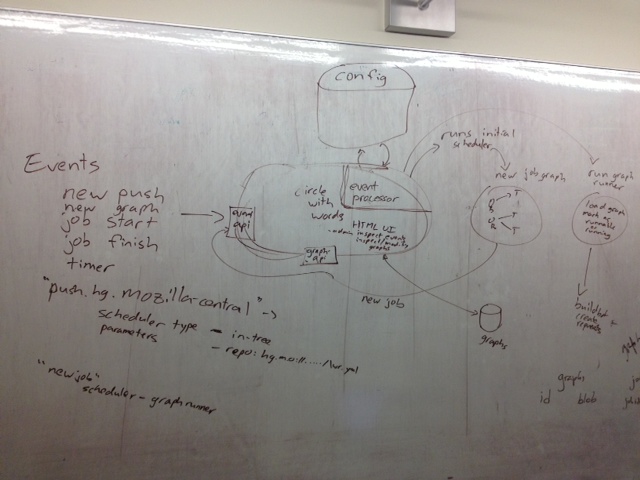
I already wrote a bit about the dependency graph here, and :catlee wrote about it here. While I was writing part 2, it became clear that
-
I had a lot more ideas about the dependency graph, enough for its own blog post, and
-
since I want to tackle writing the dependency graph first, solidifying my ideas about it beforehand would be beneficial to writing it.
I've been futzing around with graphviz with :hwine's help. Not half as much fun as drawings on napkins, but hopefully they make sense. I'm still thinking things through.
jobs and graphs
A quick look at TBPL was enough to convince me that the dependency graph would be complex enough just describing the relationships between jobs. The job details should be separate. Per-checkin, nightly, and periodic-PGO dependency graphs trigger overlapping sets of jobs, so avoiding duplicate job definitions is a plus.
We'll need to submit both the dependency graph and the associated job definitions to LWR together. More on how I think jobs and graphs could work in the db below in part 5.
For phase 1, I think job definitions will only cover enough to feed into buildbot and have them work.
dummy jobs
-
In my initial dependency graph thoughts, I mentioned breakpoint jobs as a throwaway idea, but it's stuck with me.
We could use these at the beginning of graphs that we want to view or edit in the web app before proceeding. Or if we submit an experimental patch to Try and want to verify the results after a specific job or set of jobs before proceeding further. Or if we want to represent QA signoff in a release graph, and allow them to continue the release via the web app.
I imagine we would want a request timeout on this breakpoint, after which it's marked as timed out, and all child jobs are skipped. I imagine we'd also want to set an ACL on at least a subset of these, to limit who can sign off on releases.
Also in releases, we have simple notification jobs that send email when the release has passed certain milestones. We could later potentially support IRC pings and bug comments.
A highly simplified representation of part of a release:

We currently continue the release via manual Release Engineering intervention, after we see an email "go". It would be great to represent it in the dependency graph and give the correct group of people access. Less RelEng bottleneck.
-
We could also have timer jobs that pause the graph until either cancelled or the timeout is hit. So if you want this graph to run at 7pm PST, you could schedule the graph with an initial timer job that marks itself successful at 7, triggering the next steps in the graph.
-
In buildbot, we currently have a dummy factory that sleeps 5 and exits successfully. We used this back in the dark ages to skip certain jobs in a release, since we could only restart the release from the beginning; by replacing long-running jobs with dummy jobs, we could start at the beginning and still skip the previously successful portions of the release.
We could use dummy jobs to:
-
simplify the relationships between jobs. In the above graph, we avoided a many-to-many relationship by inserting a notification job in between the linux jobs and the updates.
-
trigger when certain groups of jobs finish (e.g. all linux64 mochitests), so downstream jobs can watch for the dummy job in Pulse rather than having to know how many chunks of mochitests we expect to run, and keep track as each one finishes.
-
quickly test dependency graph processing: instead of waiting for a full build or test, replace it with a dummy job. For instance, we could set all the jobs of a type to "success" except one "timed out; retry" to test max retry limits quickly. This assumes we can set custom exit statuses for each dummy job, as well as potentially pointing at pre-existing artifact manifest URLs for downstream jobs to reference.
Looking at this list, it appears to me that timer and breakpoint jobs are pretty close in functionality, as are notification and dummy (status?) jobs. We might be able to define these in one or two job types. And these jobs seem simple enough that they may be runnable on the graph processing pool, rather than calling out to SlaveAPI/MozPool for a new node to spawn a script on.
statuses
At first glance, it's probably easiest to reuse the set of TBPL statuses: success, warning, failure, exception, retry. But there are also the grey statuses 'pending' and 'running'; the pink status 'cancelled'; and the statuses 'timed out', and 'interrupted' which are subsets of the first five statuses.
Some statuses I've brainstormed:
-
inactive (skipped during scheduling)
-
request cancelled
-
pending blocked by dependencies
-
pending blocked by infrastructure limits
-
skipped due to coalescing
-
skipped due to dependencies
-
request timed out
-
running
-
interrupted due to user request
-
interrupted due to network/infrastructure/spot instance interrupt
-
interrupted due to max runtime timeout
-
interrupted due to idle time timeout (no output for x seconds)
-
completed successful
-
completed warnings
-
completed failure
-
retried (auto)
-
retried (user request)
The "completed warnings" and "completed failure" statuses could be split further into "with crash", "with memory leak", "with compilation error", etc., which could be useful to specify, but are job-type-specific.
If we continue as we have been, some of these statuses are only detectable by log parsing. Differentiating these statuses allows us to act on them in a programmatic fashion. We do have to strike a balance, however. Adding more statuses to the list later might force us to revisit all of our job dependencies to ensure the right behavior with each new status. Specifying non-useful statuses at the outset can lead to unneeded complexity and cruft. Perhaps 'state' could be separated from 'status', where 'state' is in the set ('inactive', 'pending', 'running', 'interrupted', 'completed'); we could also separate 'reasons' and 'comments' from 'status'.
Timeouts are split into request timeouts or runtime timeouts (idle timeouts, max job runtime timeouts). If we hit a request timeout, I imagine the job would be marked as 'skipped'. I also imagine we could mark it as 'skipped successful' or 'skipped failure' depending on configuration: the former would work for timer jobs, especially if the request timeout could be specified by absolute clock time in addition to relative seconds elapsed. I also think both graphs and jobs could have request timeouts.
I'm not entirely sure how to coalesce jobs in LWR, or if we want to. Maybe we leave that to graph and job prioritization, combined with request timeouts. If we did coalesce jobs, that would probably happen in the graph processing pool.
For retries, we need to track max [auto] retries, as well as job statuses per run. I'm going to go deeper into this below in part 5.
relationships
For the most part, I think relationships between jobs can be shown by the following flowchart:

If we mark job 2 as skipped-due-to-dependencies, we need to deal with that somehow if we retrigger job 1. I'm not sure if that means we mark job 2 as "pending-blocked-by-dependencies" if we retrigger job 1, or if the graph processing pool revisits skipped-due-to-dependencies jobs after retriggered jobs finish. I'm going to explore this more in part 5, though I'm not sure I'll have a definitive answer there either.
It should be possible, at some point, to block the next job until we see a specific job status:
-
don't run until this dependency is finished/cancelled/timed out
-
don't run unless the dependency is finished and marked as failure
-
don't run unless the dependency is finished and there's a memory leak or crash
For the most part, we should be able to define all of our dependencies with this type of relationship: block this job on (job X1 status Y1, job X2 status Y2, ...). A request timeout with a predefined behavior-on-expiration would be the final piece.
I could potentially see more powerful commands, like "cancel the rest of the [downstream?] jobs in this graph", or "retrigger this other job in the graph", or "increase the request timeout for this other job", being potentially useful. Perhaps we could add those to dummy status jobs. I could also see them significantly increasing the complexity of graphs, including the potential for infinite recursion in some constructs.
I think I should mark any ideas that potentially introduce too much complexity as out of scope for phase 1.
branch specific definitions
Since job and graph definitions will be in-tree, riding the trains, we need some branch-specific definitions. Is this a PGO branch? Are nightlies enabled on this branch? Are all products and platforms enabled on this branch?
This branch definition config file could also point at a revision in a separate, standalone repo for its dependency graph + job definitions, so we can easily refer to different sets of graph and job definitions by SHA. I'm going to explore that further in part 5.
I worry about branch merges overwriting branch-specific configs. The inbound and project branches have different branch configs than mozilla-central, so it's definitely possible. I think the solution here is a generic branch-level config, and an optional branch-named file. If that branch-named file doesn't exist, use the generic default. (e.g. generic.json, mozilla-inbound.json) I know others disagree with me here, but I feel pretty strongly that human decisions need to be reduced or removed at merge time.
graphs of graphs
I think we need to support graphs-of-graphs. B2G jobs are completely separate from Firefox desktop or Fennec jobs; they only start with a common trigger. Similarly, win32 desktop jobs have no real dependencies on macosx desktop jobs. However, it's useful to refer to them as a single set of jobs, so if graphs can include other graphs, we could create a superset graph that includes the appropriate product- and platform- specific graphs, and trigger that.
If we have PGO jobs defined in their own graph, we could potentially include it in the per-checkin graph with a branch config check. On a per-checkin-PGO branch, the PGO graph would be included and enabled in the per-checkin graph. Otherwise, the PGO graph would be included, but marked as inactive; we could then trigger those jobs as needed via the web app. (On a periodic-PGO branch, a periodic scheduler could submit an enabled PGO graph, separate from the per-checkin graph.)
It's not immediately clear to me if we'll be able to depend on a specific job in a subgraph, or if we'll only be able to depend on the entire subgraph finishing. (For example: can an external graph depend on the linux32 mochitest-2 job finishing, or would it need to wait until all linux32 jobs finish?) Maybe named dummy status jobs will help here: graph1.start, graph1.end, graph1.builds_finished, etc. Maybe I'm overthinking things again.
We need a balancing act between ease of reading and ease of writing; ease of use and ease of maintenance. We've seen the mess a strong imbalance can cause, in our own buildbot configs. The fact that we're planning on making the final graph easily viewable and testable without any infrastructure dependencies helps, in this regard.
graphbuilder.py
I think graphbuilder.py, our [to be written] dependency graph generator, may need to cover several use cases:
-
Create a graph in an api-submittable format. This may be all we do in phase 1, but the others are tempting...
-
Combine graphs as needed, with branch-specific definitions, and user customizations (think TryChooser and per-product builds).
-
Verify that this is a well-formed graph.
-
Run other graph unit tests, as needed.
-
Potentially output graphviz files for user-friendly local graph visualization?
-
It's unclear if we want it to also do the graph+job submitting to the api.
I think the per-checkin graph would be good to build first; the nightly and PGO graphs, as well as the branch-specific defines, might also be nice to have in phase 1.
I have 4 more sections I wrote skeletons for. Since those sections are more db-oriented, I'm going to move those into a part 5.
In part 1, I covered where we are currently, and what needs to change to scale up.
In part 2, I covered a high level overview of LWR.
In part 3, I covered some hand-wavy LWR specifics, including what we can roll out in phase 1.
In part 5, I'm going to cover some dependency graph db specifics.
Now I'm going to meet with the A-team about this, take care of some vcs-sync tasks, and start writing some code.